利用 IP 核对 CPU 进行封装
IP 核(知识产权核):是那些己验证的、可重利用的、具有某种确定功能的 IC 模块。为了让我们实现的 CPU 能够在开发板上面进行输出,我们需要将在测试过程中输入的几个模块进行 IP 核封装:
- 指令存储器 Instruction Memory
- 数据存储器 Data Memory
这样,我们就可以将 CPU 进行综合、实现以及烧入开发板,从而进行外设的控制,实现 CPU 的真正功能。
封装指令存储器 Instruction Memory
指令存储器的工作主要就是根据 PC 输入的指令地址,输出相对应的指令。在我们自己的实现过程中,我们是这样设计指令存储器的:
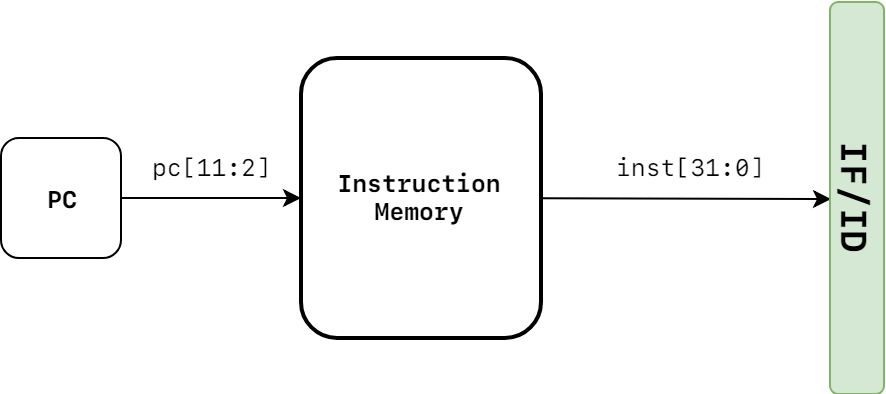
其中输入的 wire[11:2] PC 就是取指地址,输出的就是指令本身,十六进制的 wire[31:0] instruction。具体的代码实现如下:
module instruction_memory(
input wire[11:2] instruction_addr, // PC fetch instruction address
output wire[31:0] instruction // IM fetch instruction from register
);
reg[31:0] im[`IM_LENGTH:0];
assign instruction = im[instruction_addr];
endmodule
在 Vivado 中,我们可以将这部分直接利用 IP 核进行生成,从而将指令(也就是 MIPS 汇编利用 MARS 编译出的机器码)直接写入 Instruction Memory 中,烧入开发板,实现在开发板上运行我们自己实现的指令的功能。
我们找到左侧边栏的 IP Catalog,点击,搜索「Distributed Memory Generator」,然后双击它:
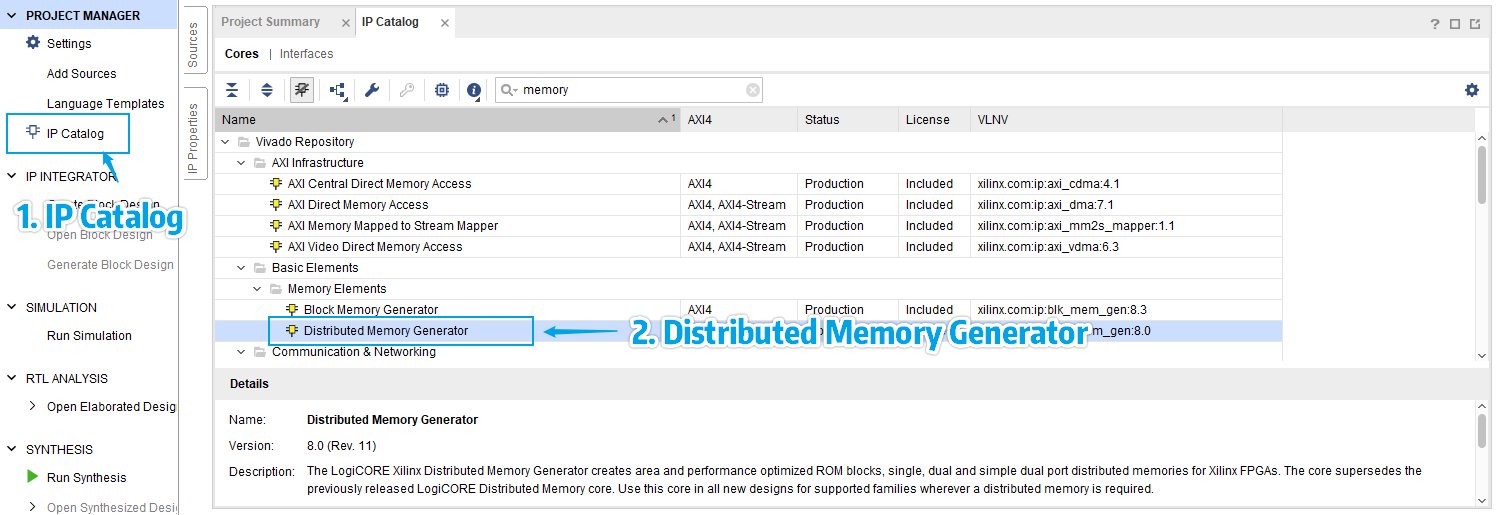
在弹出的 IP 核自定义窗口中,我们定义 IP 核名称为 instruction_mem,并选择:
- 位深度为 1024
- 位宽为 32 位
- 存储器种类为 ROM(只读)
- 并加载 RST & Initialization 中的 coe 文件
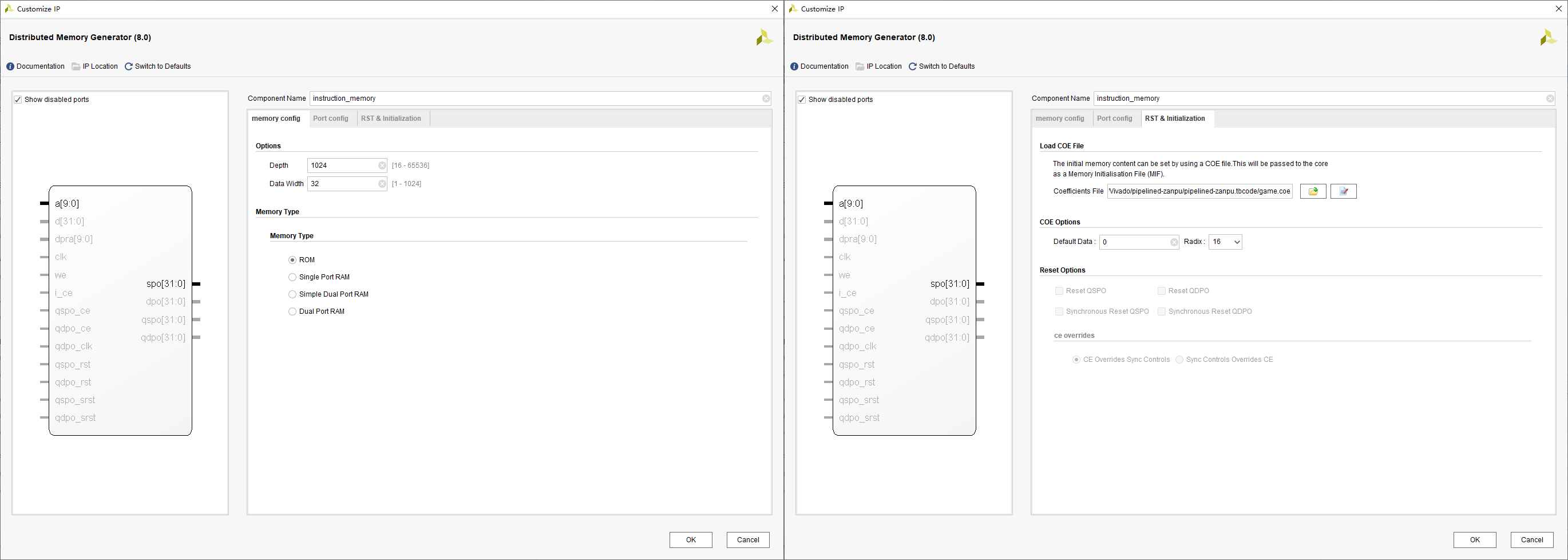
其中,coe 文件是一个 IP 核读取初始化信息(比如要运行指令、要初始化数据存储器)的文件,文件形如 instruction.coe。我们就在 coe 文件中加载我们准备执行的指令。比如:
memory_initialization_radix = 16;
memory_initialization_vector =
3c013010
... // 16 进制机器码
之后,我们在 IP Sources 中找到我们刚刚生成的 IP 核,点击 Instantiation Template,找到 instruction_mem.veo,在其中,我们可以找到初始化我们的指令存储器模块的代码:
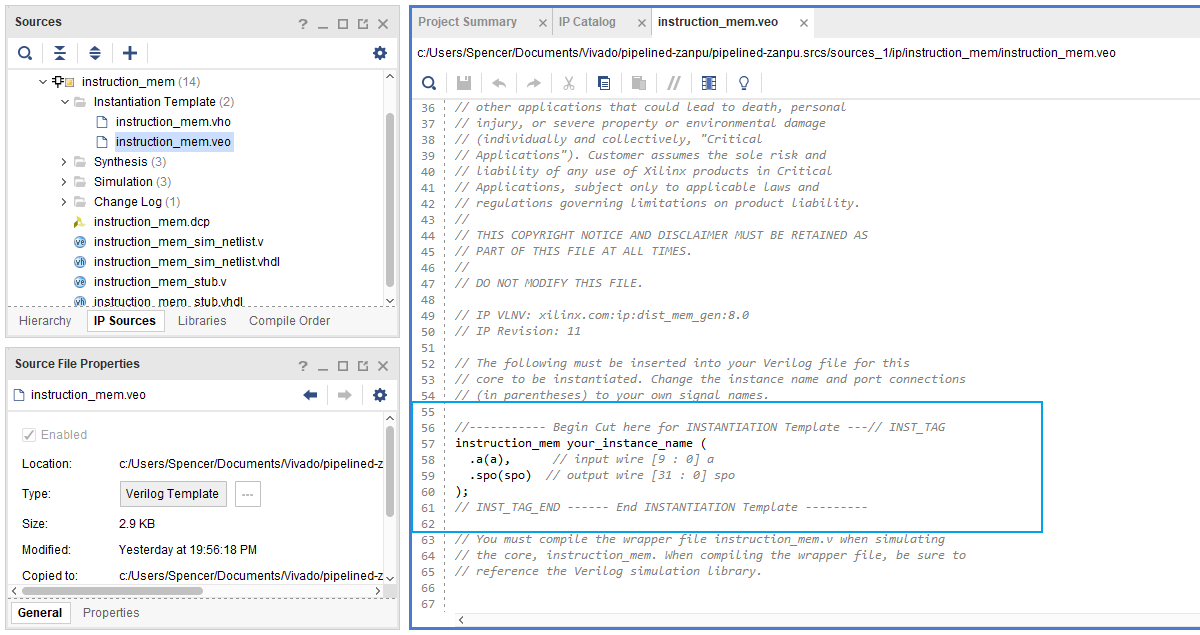
我们回到我们 CPU 的顶层模块,在其中按照上面的格式进行初始化:
instruction_mem u_instruction_mem (
.a (pc[11:2] ), // input wire [9 : 0] a
.spo (instruction) // output wire [31 : 0] spo
);
和我们之前自己实现的指令存储器进行对比:
// 自己实现的指令存储器初始化
instruction_memory u_instruction_memory(
.instruction_addr (pc[11:2] ),
.instruction (instruction )
);
可以发现,前后两次的模块调用代码几乎一致,因此我们并不需要太大改动就能将 IP 核接入我们自己实现的 CPU 中。
封装数据存储器 Data Memory
利用 IP 核封装数据存储器和指令存储器的步骤一致,我们只需要做下面几点改动:
- 修改 IP 核名称为
data_mem - 修改存储器种类为 Single Port RAM(单口输出输出 RAM)
- 并加载单独的 Data Memory COE 文件,比如:
memory_initialization_radix = 16;
memory_initialization_vector =
00000000
00000000
... // 共 1024 行,初始化 1024 个 32 位宽存储器
00000000
生成 Data Memory 之后,我们就可以在其 Instantiation Template 中找到相应的初始化模板文件 data_mem.veo,比如:
data_memory_ip your_instance_name (
.a(a), // input wire [9 : 0] a
.d(d), // input wire [31 : 0] d
.clk(clk), // input wire clk
.we(we), // input wire we
.spo(spo) // output wire [31 : 0] spo
);
我们再和之前自己实现的 Data Memory 进行对比:
data_memory u_data_memory(
.clk (clk ),
.en_mem_write (en_mem_write_mem ),
.mem_addr (alu_result_out[11:2] ),
.write_mem_data (reg2_data_mem ),
.read_mem_data (read_mem_data )
);
因此,我们也可以非常方便的将 IP 核生成的 Data Memory 直接嵌入我们的 CPU 中,和最初仿真的方法一样,进行测试。
仿真、测试
我们运行一个斐波那契数列的样例代码:
# Compute first twelve Fibonacci numbers and put in array, then print
.data
fibs: .word 0 : 20 # "array" of 20 words to contain fib values
nouse: .word 0
size: .word 20 # size of "array"
.text
la $t0, fibs # $t0 = &fibs
la $t5, size # $t5 = &size
lw $t5, 0($t5) # $t5 = *$t5 --> $t5 = 20
li $t2, 1 # $t2 = 1
sw $t2, 0($t0) # store F[0] with 1
sw $t2, 4($t0) # store F[1] with 1
ori $t6, $zero, 2 # $t6 = 2
sub $t1, $t5, $t6 # the number of loop is (size-2)
ori $t7, $zero, 1 # the lastest loop
Loop:
slt $t4, $t1, $t7 # $t4 = ($t1 < 1) ? 1 : 0
beq $t4, $t7, Loop_End # repeat if not finished yet error
lw $a0, 0($t0) # $a0 = F[n]
lw $a1, 4($t0) # $a1 = F[n+1]
jal fibonacci # $v0 = fibonacci( F[n], F[n+1] )
sw $v0, 8($t0) # store F[n+2]
addi $t0, $t0, 4 # $t0 point to F[n+1]
addi $t1, $t1, -1 # loop counter decreased by 1
j Loop
Loop_End:
lui $t6, 0xABCD # $t6 = 0xABCD0000 # addi $t6,$0,0xABCD#
addi $t0, $t0, 8 # point to the next address of the lastest fibonacci unit
sw $t6, 0($t0) # *$t0 = $t6
Loop_Forever:
j Loop_Forever # loop forever
fibonacci :
add $v0, $a0, $a1 # $v0 = x + y
jr $ra # return
这段代码主要功能是将 Register File 中的 $4 和 $5 初始化为 1,并将 $4 + $5 的结果写入 $2 中,不断重复 20 次,得到第 20 项斐波那契数列的值。利用 MARS,我们将 MIPS 汇编编译成机器码,为了处理跳转时出现的控制冲突,我们在涉及到冲突的地方加上空指令 sll $0, $0, 0。
编译完成的机器码大致如下(点击展开):
memory_initialization_radix=16;
memory_initialization_vector=
3c011001
00000000
00000000
00000000
00000000
00000000
34280000
3c011001
342d0054
8dad0000
240a0001
ad0a0000
ad0a0004
340e0002
01ae4822
340f0001
012f602a
00000000
00000000
00000000
00000000
00000000
118f000d
00000000
00000000
8d040000
8d050004
0c10002a
00000000
00000000
ad020008
21080004
2129ffff
08100010
00000000
00000000
3c0eabcd
21080008
ad0e0000
08100027
00000000
00000000
00851020
00000000
00000000
00000000
00000000
00000000
03e00008
同时,由于这段代码涉及到了初始化存储器,我们也需要将 Data Memory 进行初始化。我们直接利用 MARS 将上述代码的代码段 .text 和数据段 .data 全部以 16 进制的格式导出,并写入 coe 文件,配置 IP 核。
之后我们开始仿真。我们直接配置仿真文件 testbench.v 如下:
`timescale 1ns / 1ps
/*
* Testbench
*/
module testbench();
reg clk;
reg rst;
// 初始化顶层模块
zanpu_top u_zanpu_top(
.clk (clk ),
.rst (rst )
);
initial begin
rst = 1;
clk = 0;
#30 rst = 0;
end
always
#20 clk = ~clk;
endmodule
运行仿真之后,我们观察 $4、$5 和 $2 号寄存器,在初始化完成之后,我们就可以看到 16 进制的斐波那契数列的计算过程。
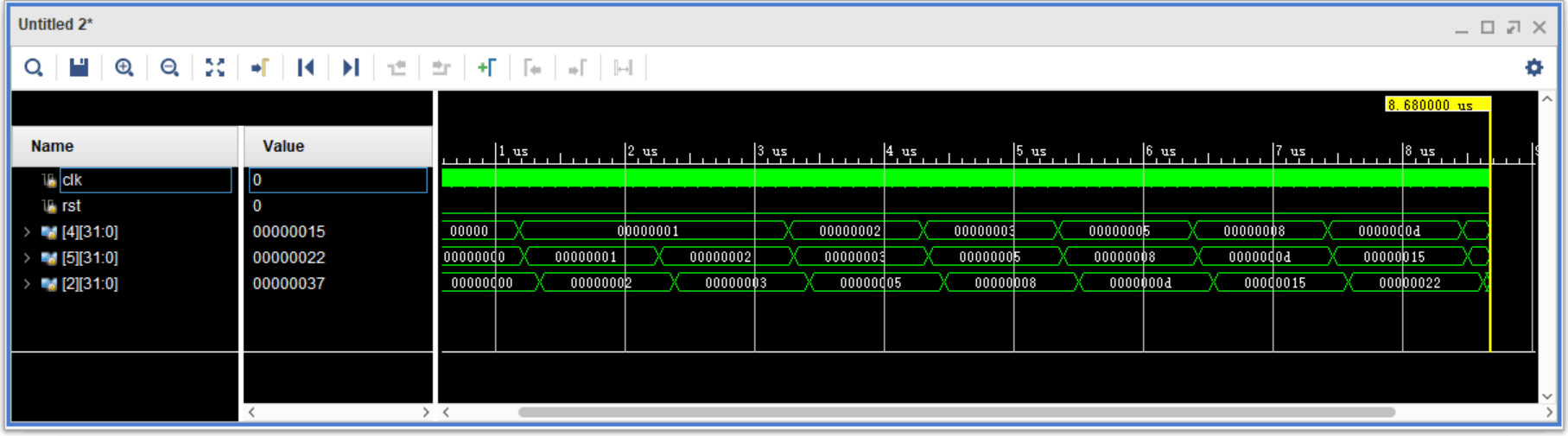
与此同时,这部分数据也被写入 Data Memory,我们同样可以抓取到。
利用 IP 核对指令和数据存储器进行封装能够让我们的代码在开发板上面运行,接下来的外设部分需要这样的操作。