Hazards 与其避免措施
在前文我们提到了:「流水线 CPU 由于会并行的执行多条指令,因此会产生数据、指令的相关性问题。」我们统称这些相关型问题为:Hazards。
Data Hazard —— 数据冲突
以下面这几条指令为例:
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
我们将其大致的五级流水执行过程画出来,并用箭头标注前后两条指令之间的数据相关(数据依赖):
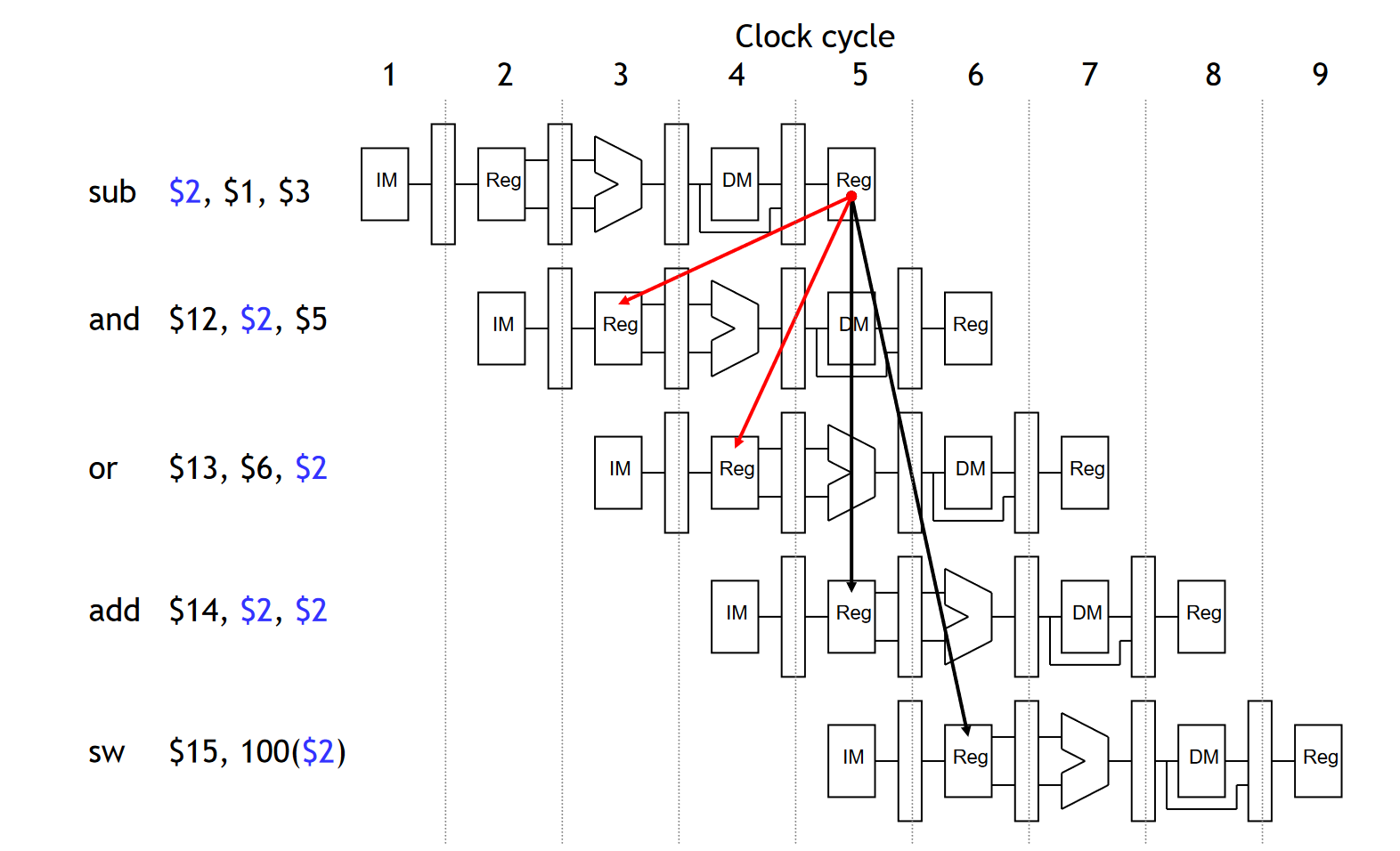
可以看到,SUB 指令的结果是 AND 指令的输入,也是 OR 指令的输入;而 ADD 指令与 SW 指令的输入同样依赖 SUB 指令。其中,红线由前指向后,因此从时间流动的角度,红线就代表一处「数据冲突」,即 Data Hazard.
解决方法:数据前递 Data Forwarding
事实上,对 SUB 指令来说,其结果的产生是在其第三流水阶段:EX,也就是整个流水线 CPU 的第三个时钟周期。而对 SUB 之后的 AND 以及 OR 来说,寄存器 $2 的值是在它们的第三阶段 EX 需要的,也就是流水线 CPU 的第 4-5 个时钟周期。纵观整个流水过程,事实上 $2 的值是在第 3 个时钟周期产生,并在第 4-5 个时钟周期需要,因此我们只需要越过流水线五个阶段中 WB(WriteBack)的过程,让第 3 个时钟周期里面计算产生的 $2 寄存器值 直接赋值 给第 4-5 个时钟周期指令 ADD 以及 OR 指令即可。这种避免「Data Hazard」的方法叫做:数据前递(Data Forwarding)。
我们新增一个硬件元件:Forwarding Unit(前递组件)专门用来处理数据的前递,在出现 Data Hazard 的时候将 ALU 的输出赋予给正确的输入。下图中的 ForwardA 与 ForwardB 就是一个简单的例子:
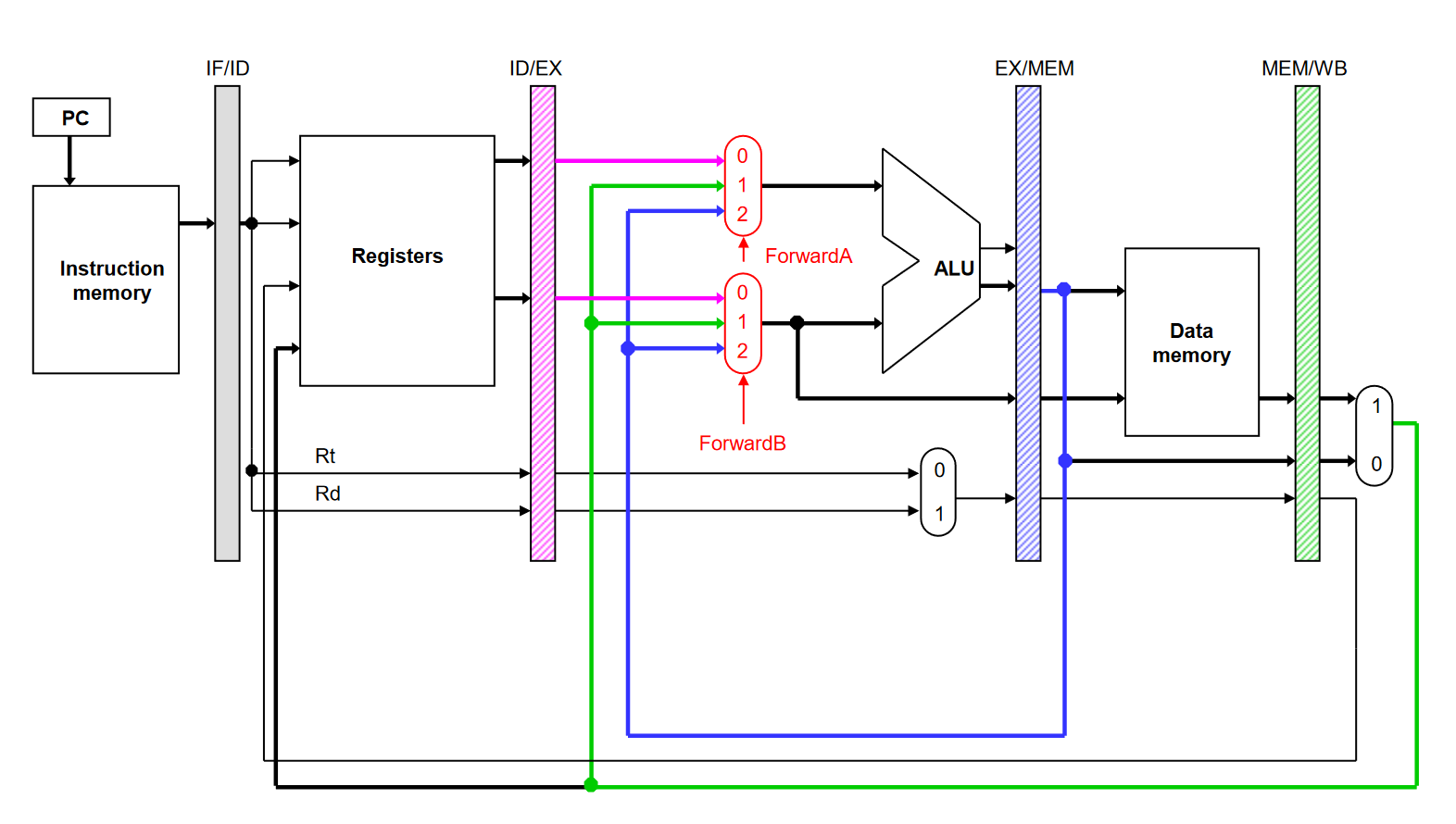
判断出现 Data Hazard 的情况
EX/MEM 类型的 Data Hazard
我们在上面例子中出现的 Data Hazard 事实上是 EX/MEM 过程的 Data Hazard,如何让硬件知道接下来的指令会触发 Data Hazard 是一个亟需解决的问题。
首先,EX/MEM Data Hazard 会出现在:
- 当前指令(比如下图中的 AND 指令)在 EX 阶段,且:
- 上一条指令(比如下图中的 SUB 指令)会写入寄存器堆(Register File,也就是下图的 $2),且:
- 上一条指令的写入地址是当前指令 EX 阶段中 ALU 输入寄存器(也就是下图的 $2)的一个
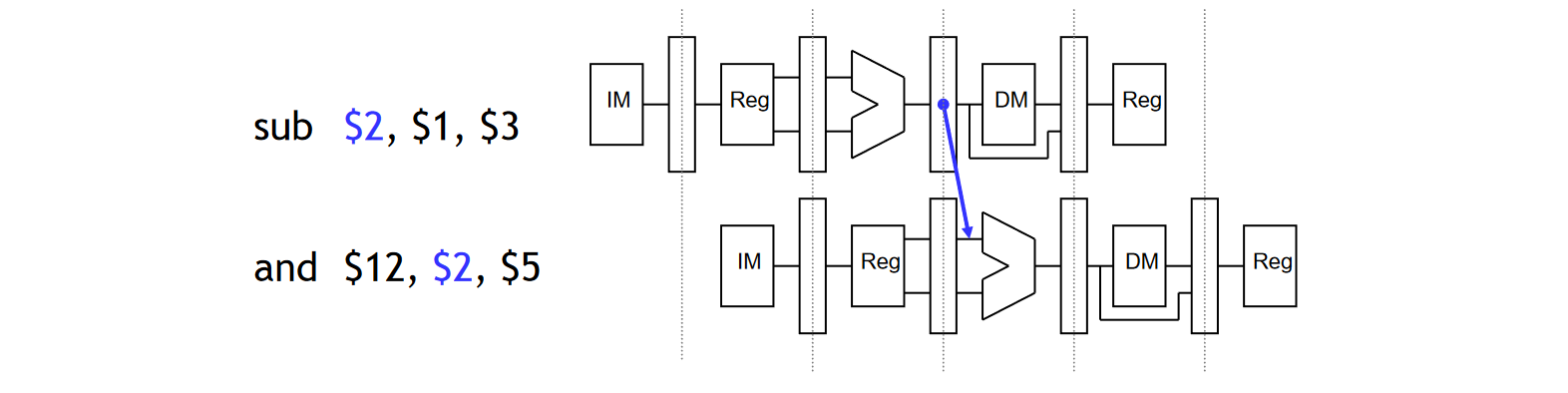
我们利用类似「类」的语法来描述流水线寄存器中的数据,比如 ID/EX.RegisterRt 就表示 ID/EX 流水线寄存器中的 rt 寄存器值。那么,EX/MEM Data Hazard 的触发条件就是:
// ALU 第一个操作数
if (EX/MEM.RegWrite = 1 &&
EX/MEM.RegisterRd == ID/EX.RegisterRs) {
ForwardA = 2
}
// ALU 第二个操作数
if (EX/MEM.RegWrite = 1 &&
ID/EX.RegisterRd == ID/EX.RegisterRt) {
ForwardB = 2
}
MEM/WB 类型的 Data Hazard
第二种会出现的 Data Hazard 就是 MEM/WB 类型的 Data Hazard.
MEM/WB Data Hazard 会出现在当前指令处于 EX 阶段,而两个时钟周期之前的指令将同一个寄存器同时更新了两次,比如:
add $1, $2, $3
add $1, $1, $4
sub $5, $5, $1
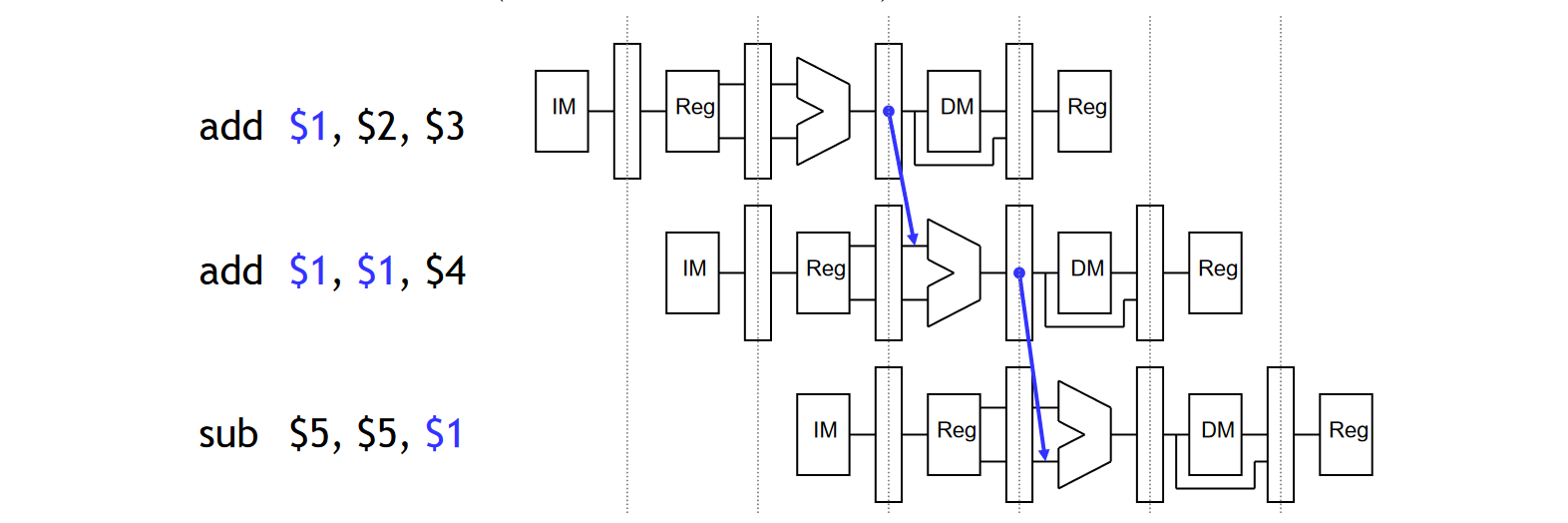
可以看到,上一条指令以及上上条指令都更新了寄存器 $1,但是只有最新的结果(也就是第二条 ADD 指令的结果)才需要被前递。因此,我们需要进行如下的处理:
// ALU 第一个操作数
if (MEM/WB.RegWrite == 1 &&
MEM/WB.RegisterRd == ID/EX.RegisterRs &&
(EX/MEM.RegisterRd != ID/EX.RegisterRs || EX/MEM.RegWrite == 0)) {
ForwardA = 1
}
// ALU 第二个操作数
if (MEM/WB.RegWrite == 1 &&
MEM/WB.RegisterRd == ID/EX.RegisterRt &&
(EX/MEM.RegisterRd != ID/EX.RegisterRt || EX/MEM.RegWrite == 0)) {
ForwardB = 1
}
新增了 Forwarding Unit 的数据通路
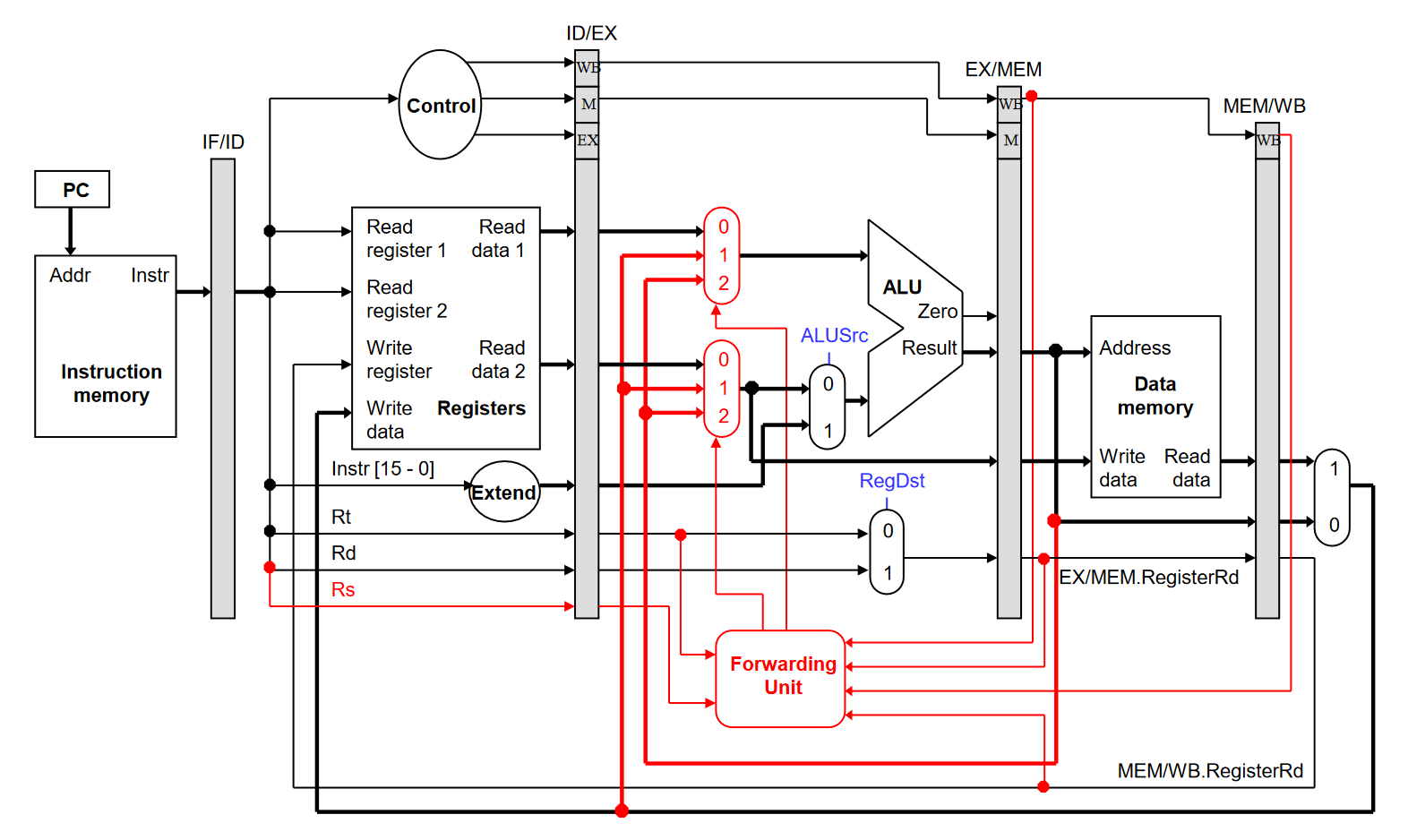
增加了 Forwarding Unit 的五级流水 CPU 已经能够处理算术运算中涉及到的 Data Hazard,但是对于 LW、SW 等涉及到存储、获取数据存储器中「字」的数据,还是会有尚未解决的问题。
事实上,MIPS 指令集中的每一条指令至多只写入一个寄存器,这让我们的 Forwarding 工作非常简单,只需要处理一个寄存器数据的前递即可。
Data Hazard —— 访存冲突
虽然前面介绍的方法规避了 ALU 算术运算的数据冲突,但是对于需要访问数据存储器的指令(比如 LW)来说,我们并不能规避类似下面的指令带来的数据冲突:
lw $2, 20($3)
and $12, $2, $5
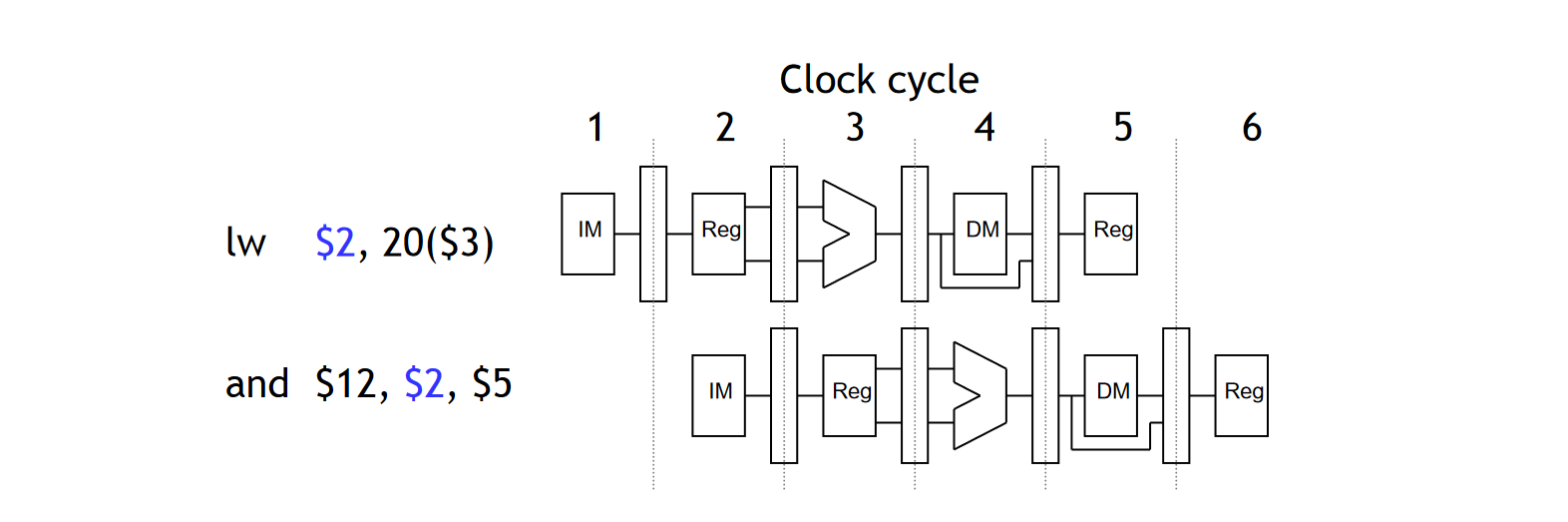
解决方法 1:Stalling and forwarding
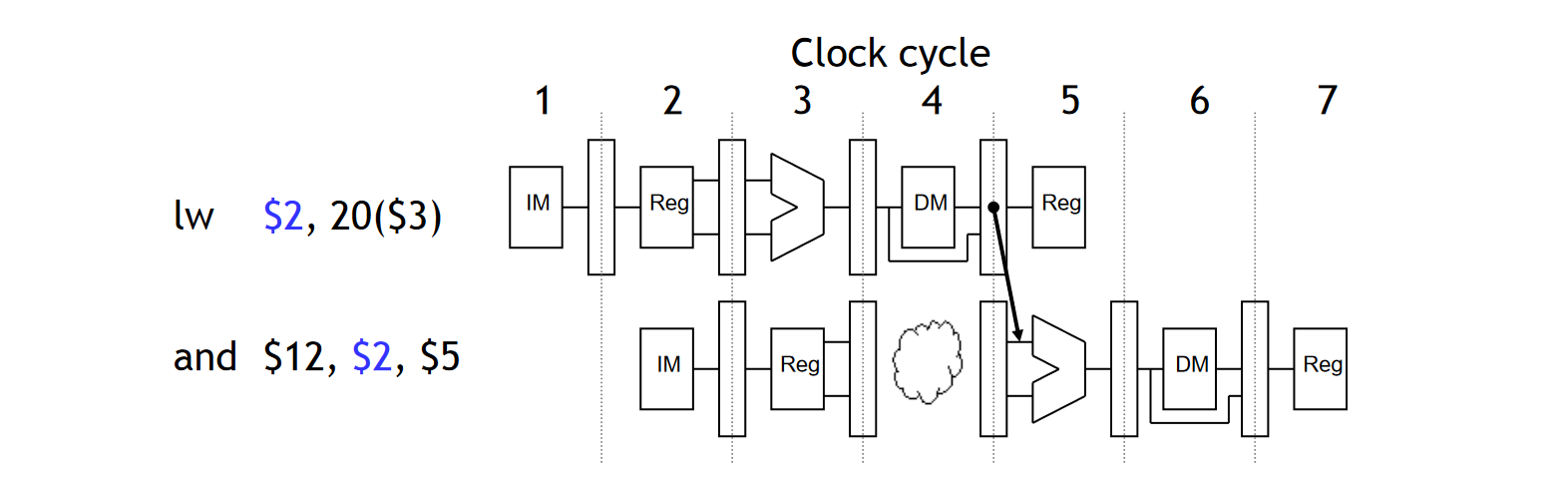
事实上,在 LW 指令的 MEM 阶段,我们就获得了相应的数据,那么,对于下一条 AND 指令,我们只需要在其 EX 阶段前将流水线 Stall 住一个时钟周期,即可将 Data Memory 的数据前递至正确的地方。这种解决方法也叫向流水线中引入一个 bubble。
但是,在现实世界中,几乎所有的指令与指令直接都存在或多或少的访存冲突,而如果我们像上面介绍的向流水线中引入 bubble,那么我们会给整个流水线造成不小的性能问题。也就是:Stalling delays the entire pipeline.
解决方法 2:Stall <=> NOP 转换
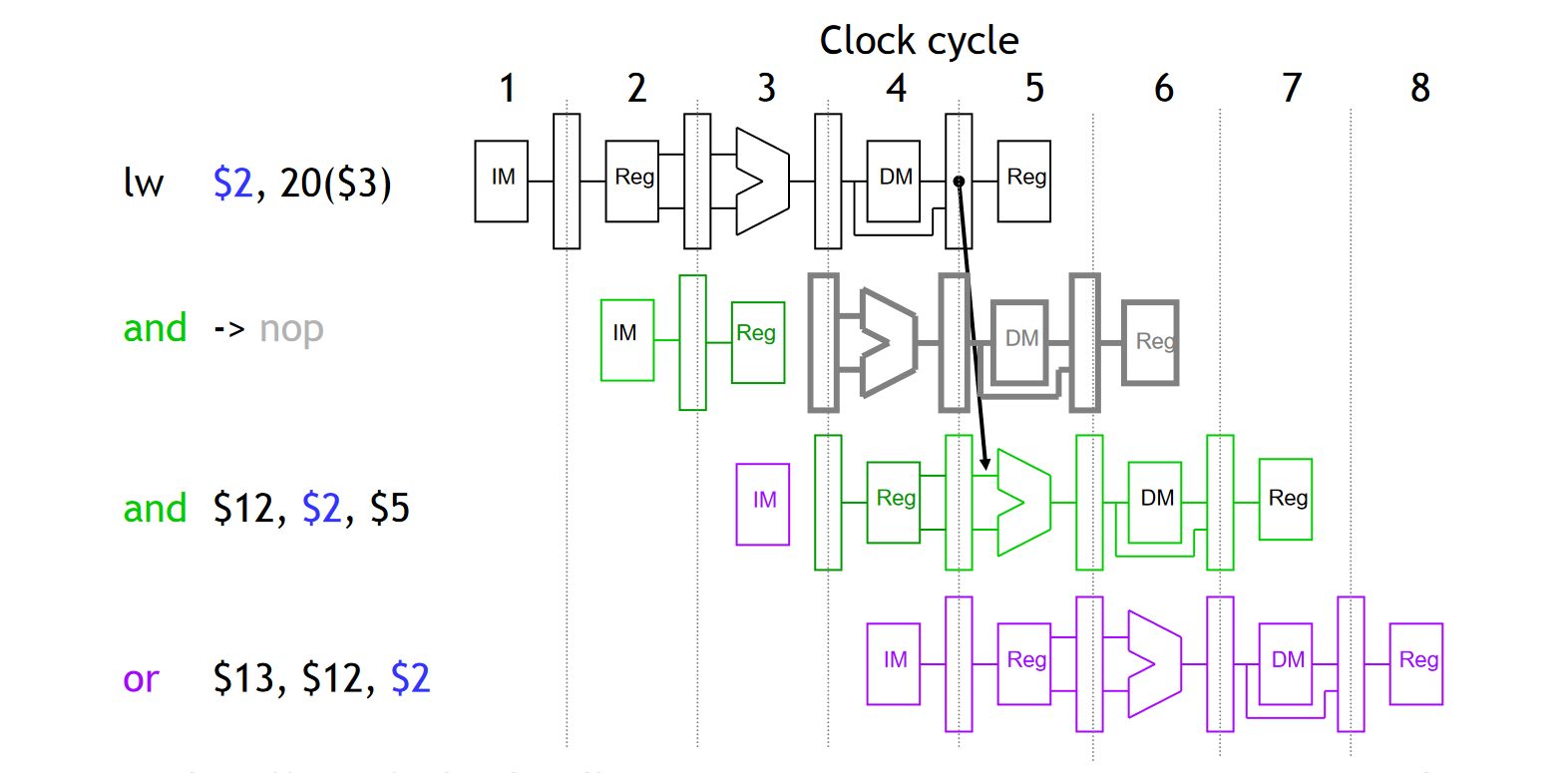
第二种更为合理的解决方法就是「引入 NOP(No Operation)指令」,比如上面介绍的例子中,指令 LW 之后的 ADD 只需要延迟一时钟周期再执行即可。于是,我们在原有的 ADD 指令之前插入一个 NOP 指令,表示这一部分不执行任何指令。这样,我们就可以在不大影响流水线 CPU 整体性能的前提下处理访存冲突。
检测访存冲突
对于「访存冲突」,我们也需要进行硬件层级的检测,以便通过 Hazard Unit 来对其进行处理。
Control Hazard
在处理指令的跳转时,我们对「是否跳转」以及「跳转目标」的判断大多都是在 EX 阶段进行的:
- 计算跳转目标地址
- 比较源寄存器的大小关系以及计算 Zero 控制信号
因此对跳转的判断大多情况下都需要在 EX 阶段才能得出结果。但是,我们在流水线 CPU 中需要知道下一条指令取哪一条,这样流水线才能顺利的顺序执行。这种情况下,我们就会遇到 Control Hazard 的问题。
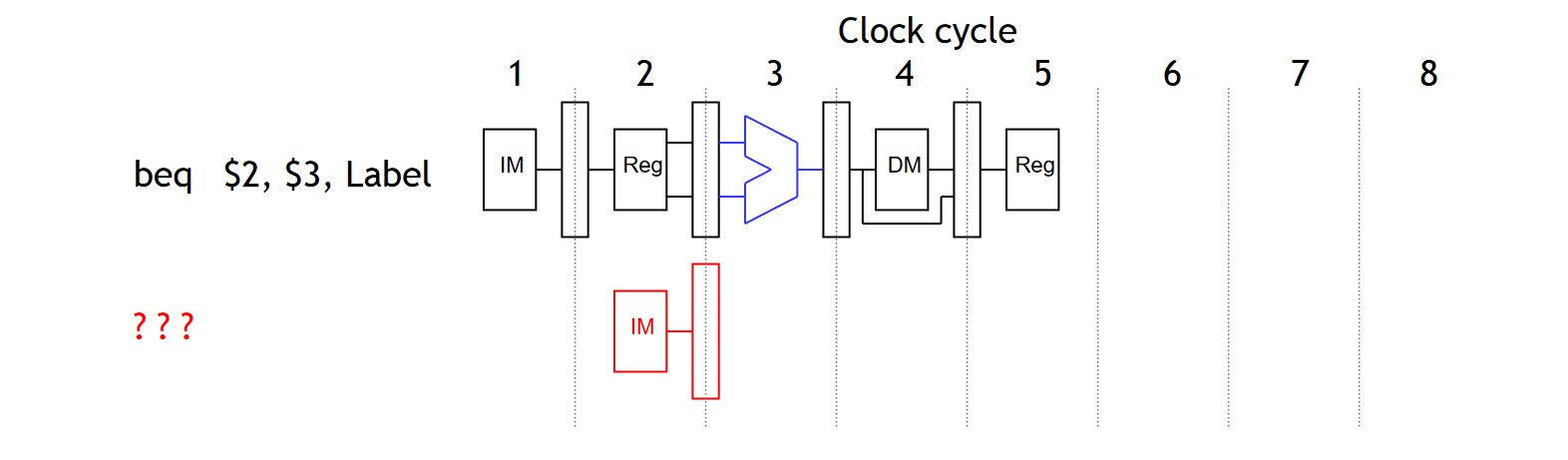
解决方法 1:Stalling
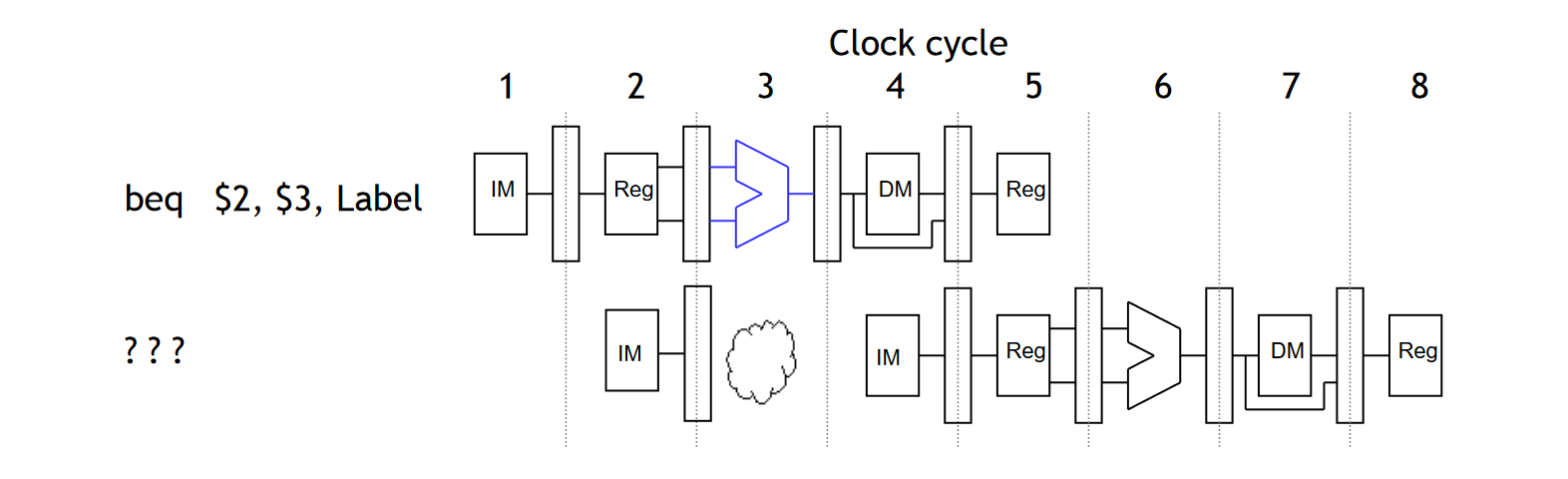
Stalling 永远都是一种解决方法,我们完全可以让跳转指令停下来,等待结果的出现,再继续执行。但是随之而来的就是性能的下降问题。因此这种方法并非最为优雅的解决方案。
解决方法 2:Branch Prediction 分支预测
第二种更为优雅的解决方法是「分支预测」。我们需要在硬件层面去预测「跳转指令」是否会被执行,然后按照预测取下一条指令。如果预测失败,那么我们就需要将错误路线上面的指令 Flush 掉,去重新加载正确的指令。
Branch Prediction 相对比较复杂,我们在下一部分进行更为具体的介绍。