分支预测 Branch Prediction
最简单的分支预测手段
最为简单的分支预测手段就是「假装全部分支都不会执行」,从硬件角度来说,这种「分支预测」的实现手段最为简单,因为我们只需要直接让 PC 进行自增,获取下一条指令即可,不需要做任何改动。
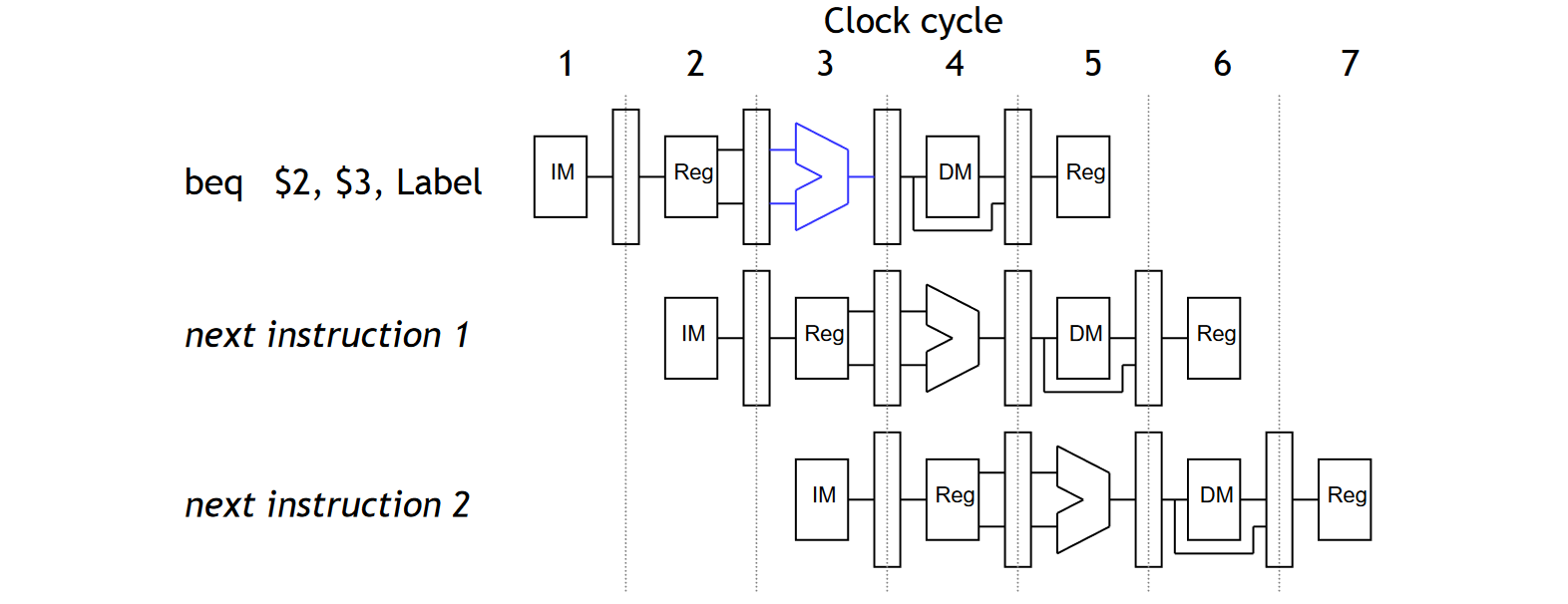
但是如果我们预测如果 出现了偏差,那我们可 需要负责 的!我们需要将已经开始执行的指令流水 Flush 掉,然后重新开始正确指令分支的执行。
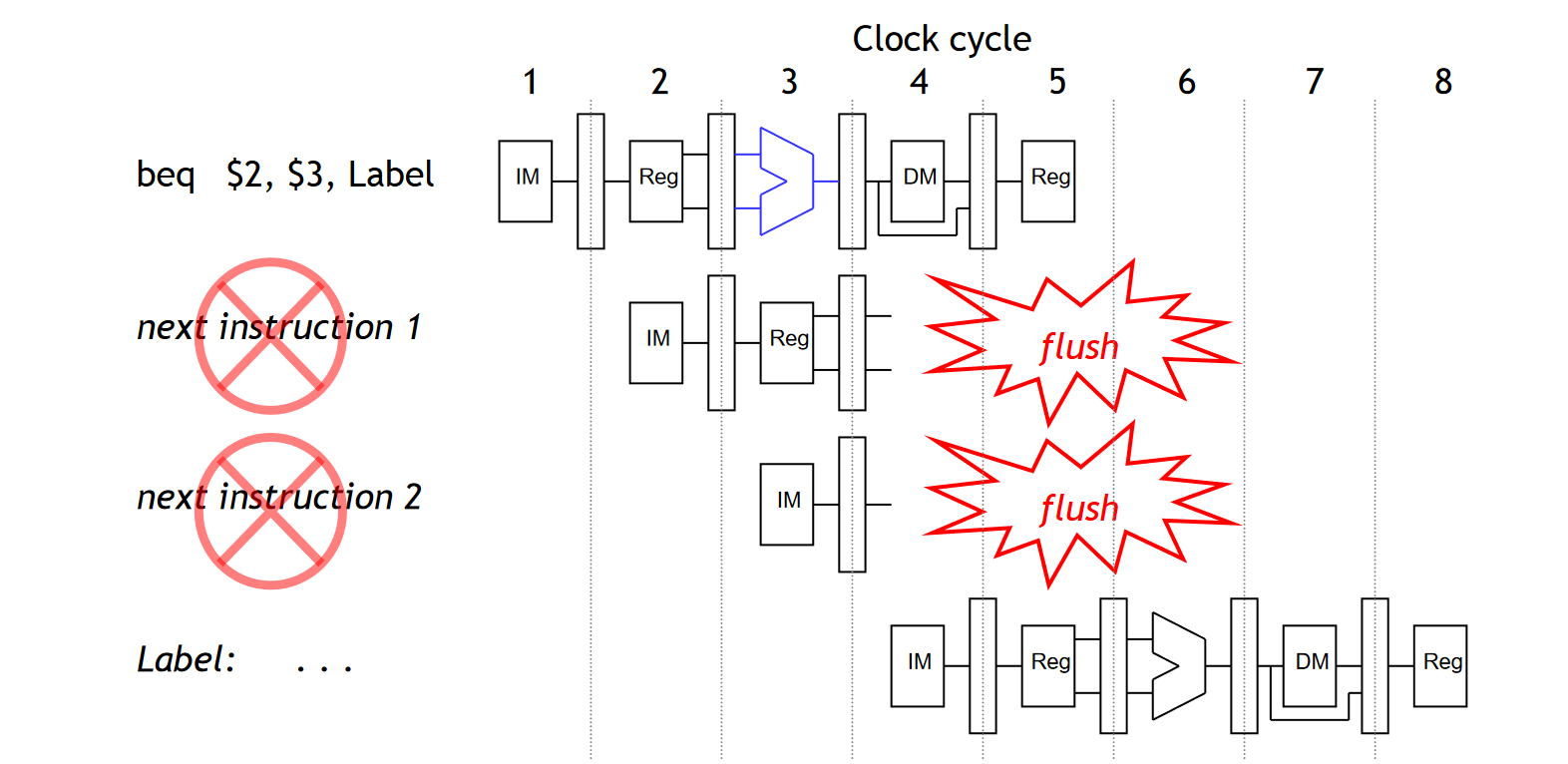
Flushing 剪枝
由于我们指令集中 BEQ 指令的判断实际上非常简单,因此我们完全可以直接将这部分判断加入 ID 阶段,在源寄存器的值读取之后直接比较二者大小即可。
这样以来,如果我们「预测失败」,我们只需要 Flush 掉一条指令。
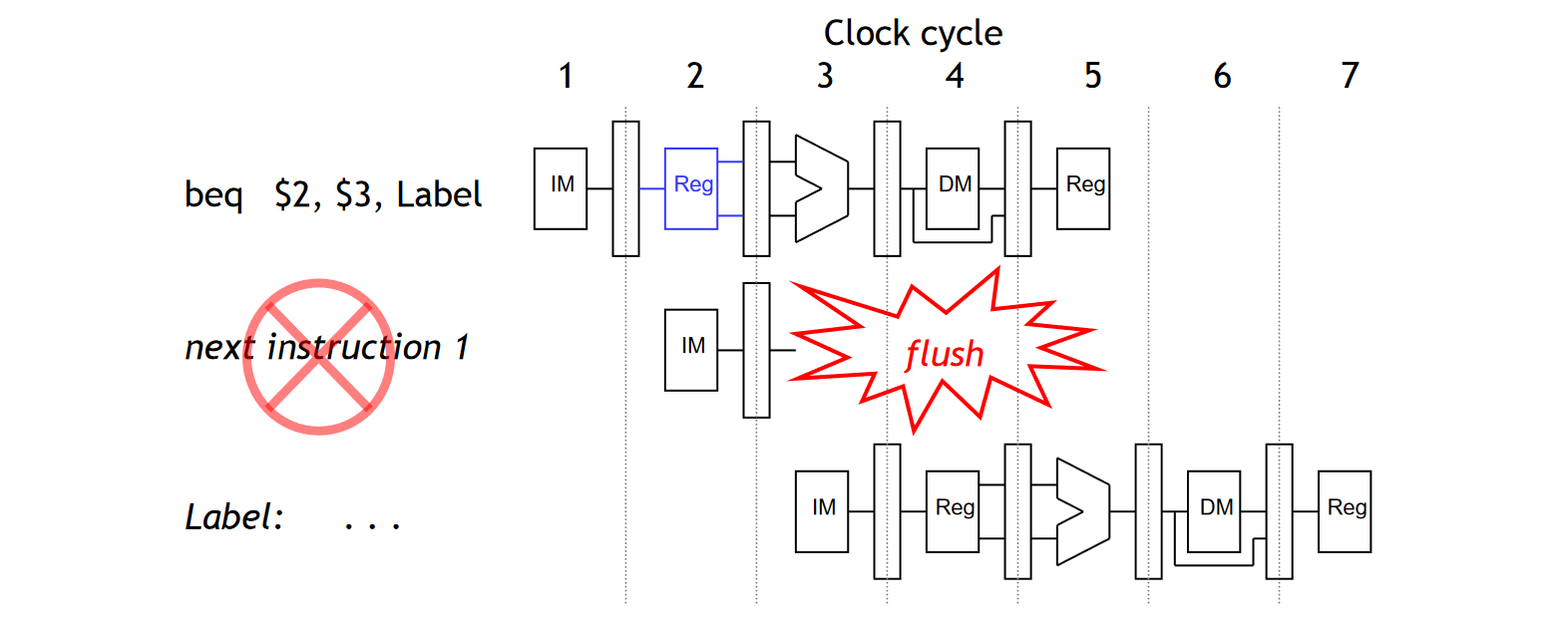
对于 BEQ 指令来说,如果 BEQ 的 rs 和 rt 是相等的,那么我们只需要将前面取来的一条指令 Flush 掉即可。我们可以 IF 阶段将需要 Flush 掉的指令用一条 NOP 指令替换,来取消这一指令。
MIPS 在实际实现过程中往往使用的是下面的指令作为 NOP:
sll $0, $0, $0
Flushing 的过程会向流水线中引入一个 bubble,代表我们这一条流水线会引入一个时钟周期的延迟。
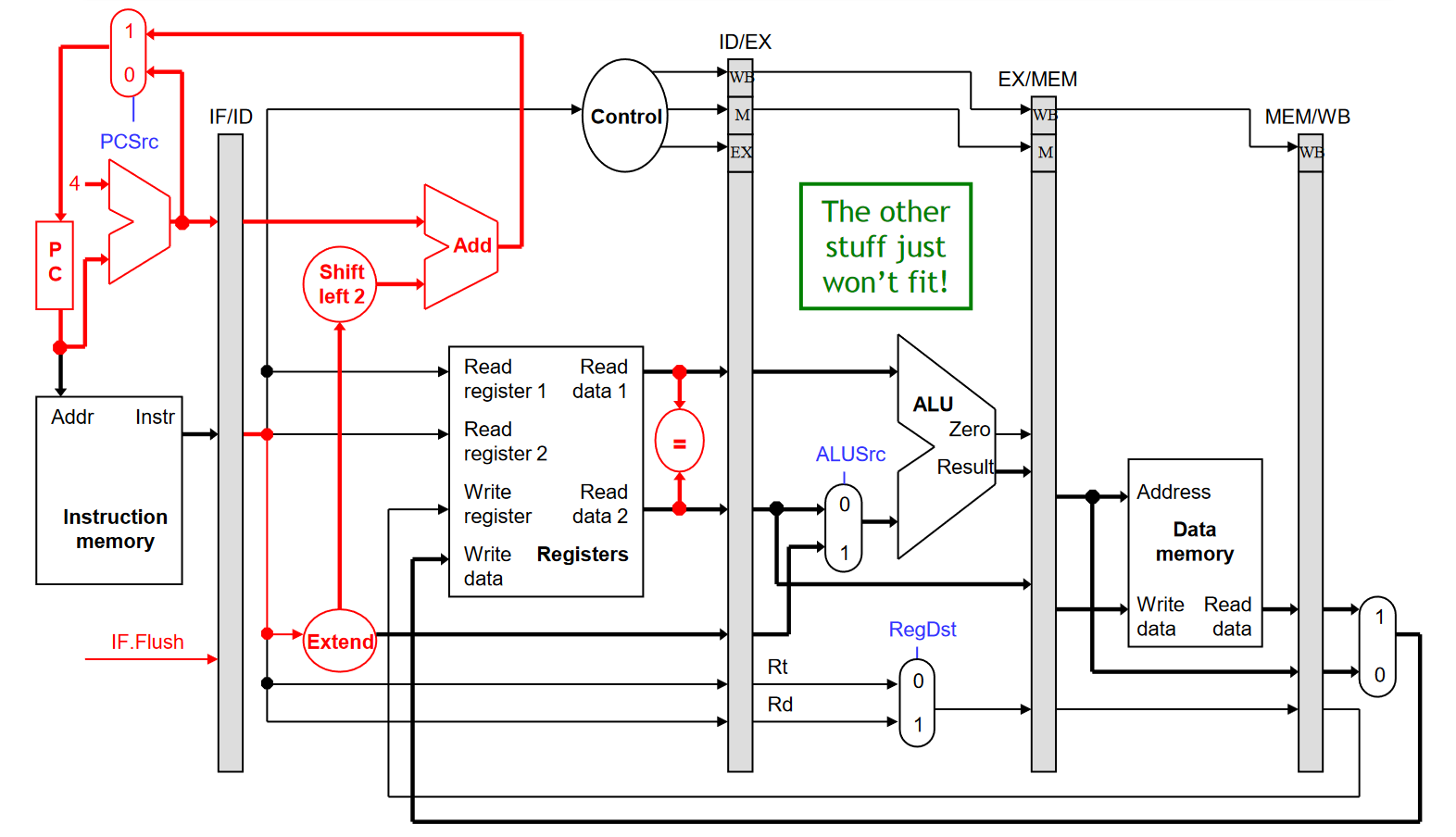
引入 Flushing 的数据通路大致如下:
总体来说,我们流水线 CPU 的 Hazards 就有这些,包括:
- Structural Hazards:由于数据通路设计问题与硬件问题导致出现结构性冲突,可以通过增加硬件的方式来解决(设计完善的数据通路不会遇到类似问题,因此我们没有介绍。)
- Data Hazards:由于指令需要尚未更新的寄存器值而出现的数据冲突。对 R-Type 指令出现的 Data Hazards 我们可以通过「数据前递」来解决;对于 Load 数据寄存器中数据出现的 hazard,我们只能 Stall 整条流水线,通过延迟进行处理
- Control Hazards:当 CPU 无法判断下一条指令取哪条好的时候出现。我们可以通过将判断步骤提前,来减少流水线的延迟;我们也可以通过「分支预测」来提高分支利用率,让正确的预测节省 CPU 的处理时间
到这里,我们就可以开始着手设计五级流水线 CPU 了。( •̀ ω •́ )y