流水线 CPU 的基础知识
以 LW 为例子对指令进行分解
指令 LW 是一个非常典型的,涉及到 CPU 执行的五个阶段的指令。CPU 一条指令执行过程中的五个大致阶段有:
- IF - Instruction Fetch:取指令
- ID - Instruction Decode:指令译码
- EX - Execute:指令执行
- MEM - Memory:访存
- WB - Writeback:结果写回
那么对于 LW 来说,这五大阶段分别需要这样的工作:
- IF:读取指令存储器 IM,获得指令
- ID:对获取的指令进行译码,得知指令为 LW
- EX:通过 ALU 计算得知取存储器的目标地址
- MEM:读取数据存储器的目标地址,获得对应数据
- WB:将取到的数据写回到目标寄存器
CPU 指令执行的优化
为了更方便的看 LW 指令的执行过程,我们去掉 PC、NPC 等分支、跳转模块,只看涉及到的模块的数据通路:
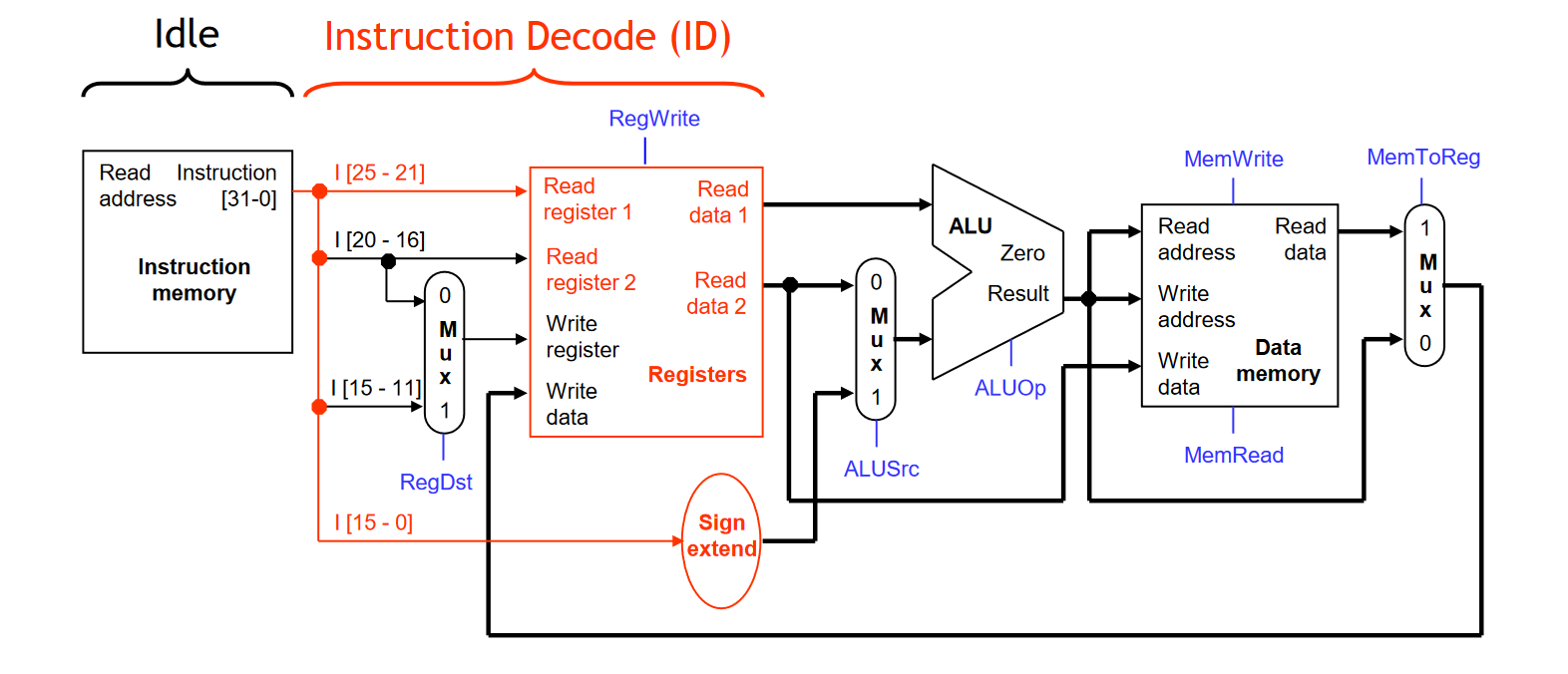
可以看到,指令执行的整个过程中,许多硬件都没有发挥任何作用,处于闲置状态。我们可以通过 Pipelining 的方式来让 CPU 的硬件从时间角度更有效的发挥作用。比如:
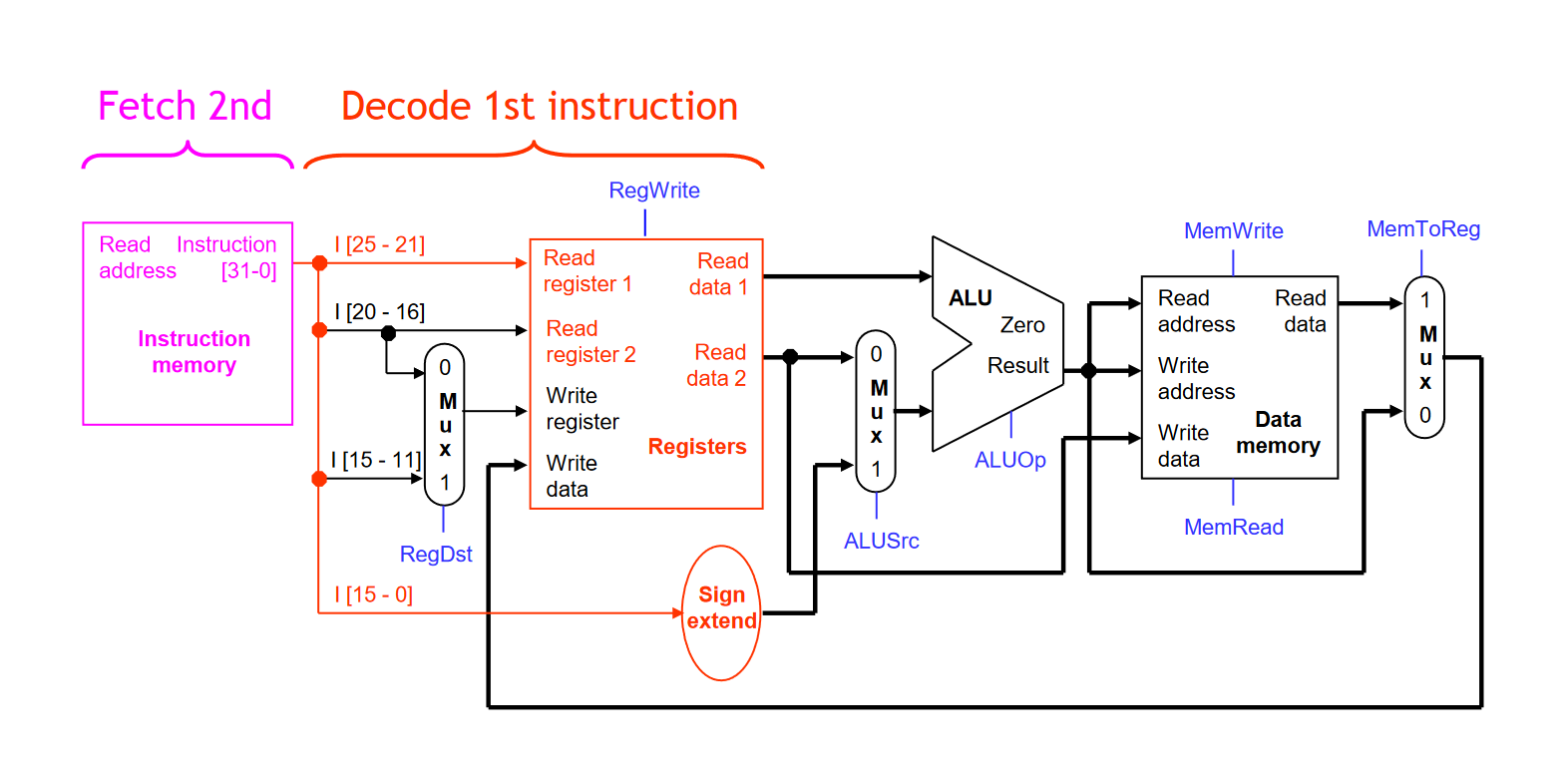
- 我们可以在 ID 模块当前指令译码的同时让 IF 模块直接加载下一条指令
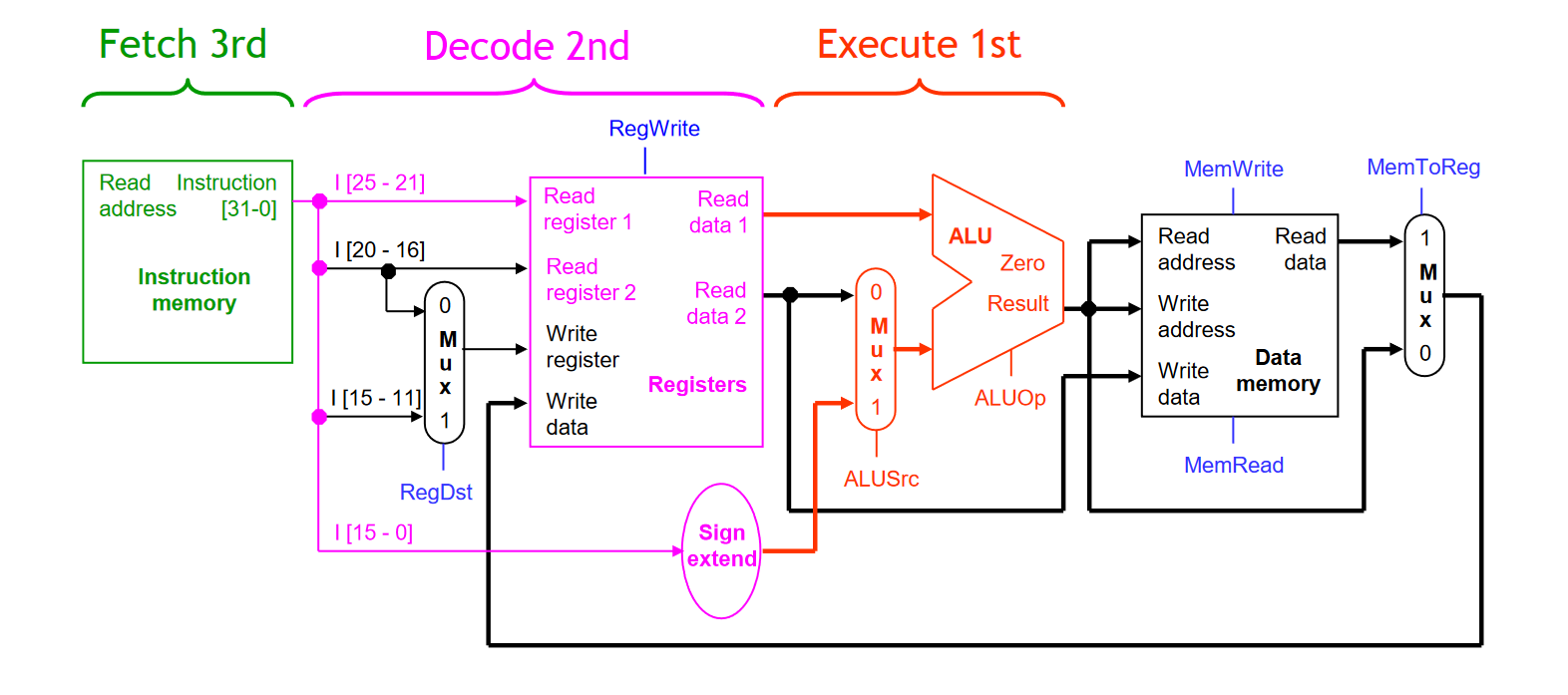
- 当然,我们也可以在前一条指令到 EX 指令执行的阶段,将加载好的当前指令进行译码,同时再加载第三条指令
等等。这也就是「流水线」CPU 的具体指令执行方式。
流水线 CPU 的设计
更为详细的说,流水线 CPU 在一条指令的执行过程中,会先将指令通过上面提到的五个基本模块进行处理:
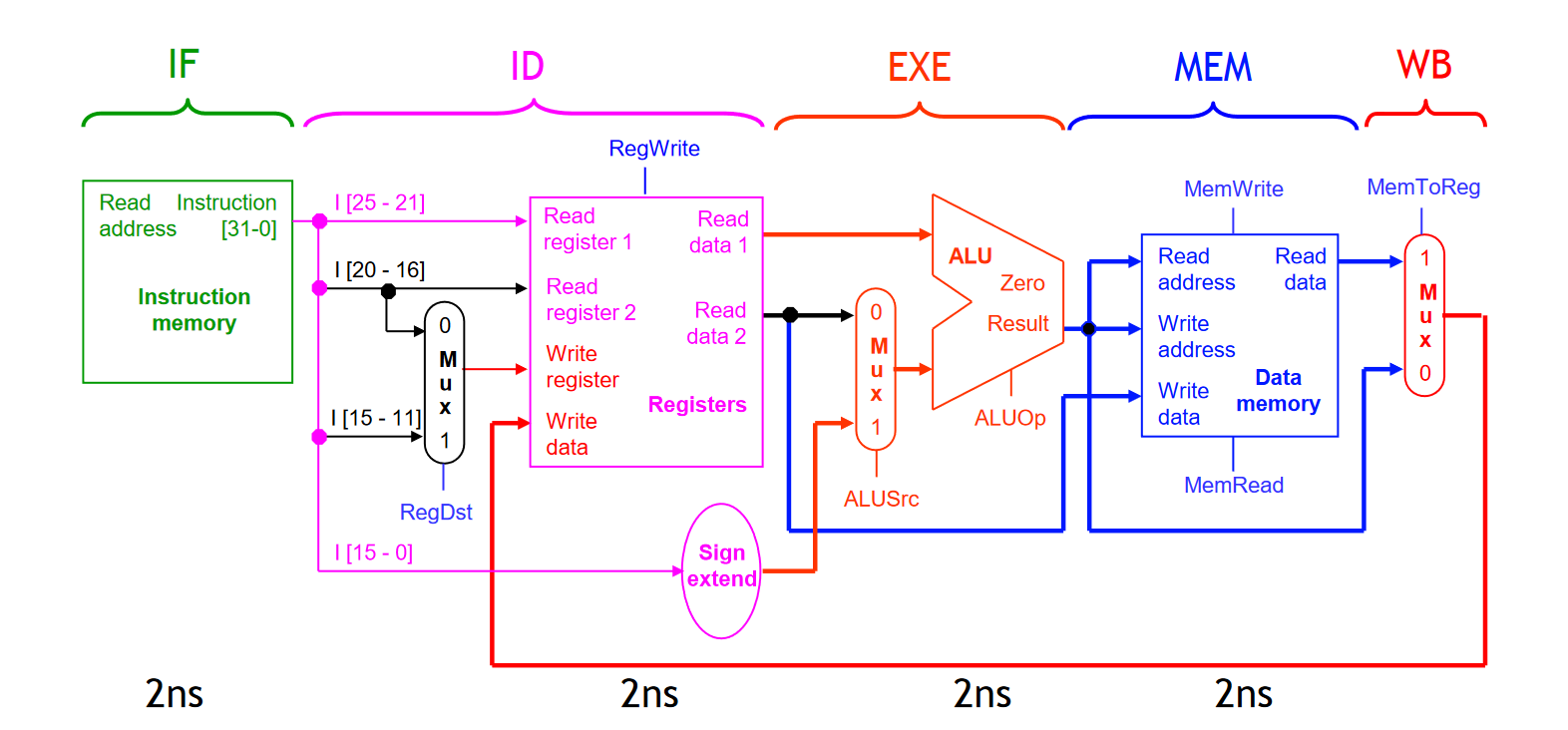
这样,利用「流水线」的思想,我们就可以将五个模块的执行过程进行组合,从时间的维度进行重叠,从而加速 CPU 指令执行的「吞吐量」,提高 CPU 执行指令的效率。
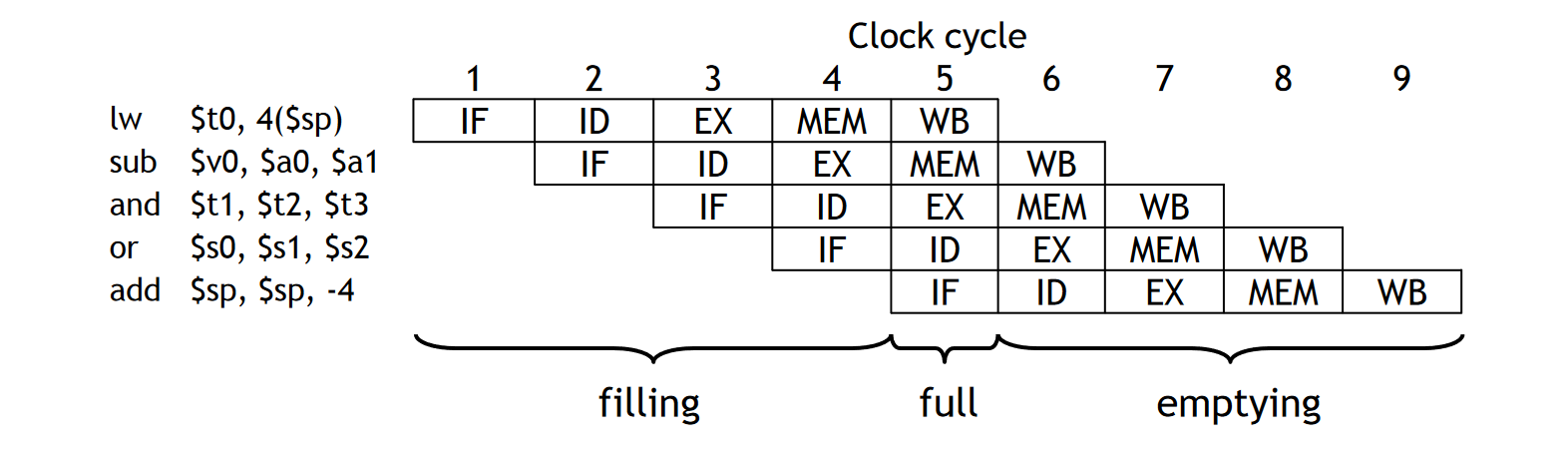
无关阶段的处理
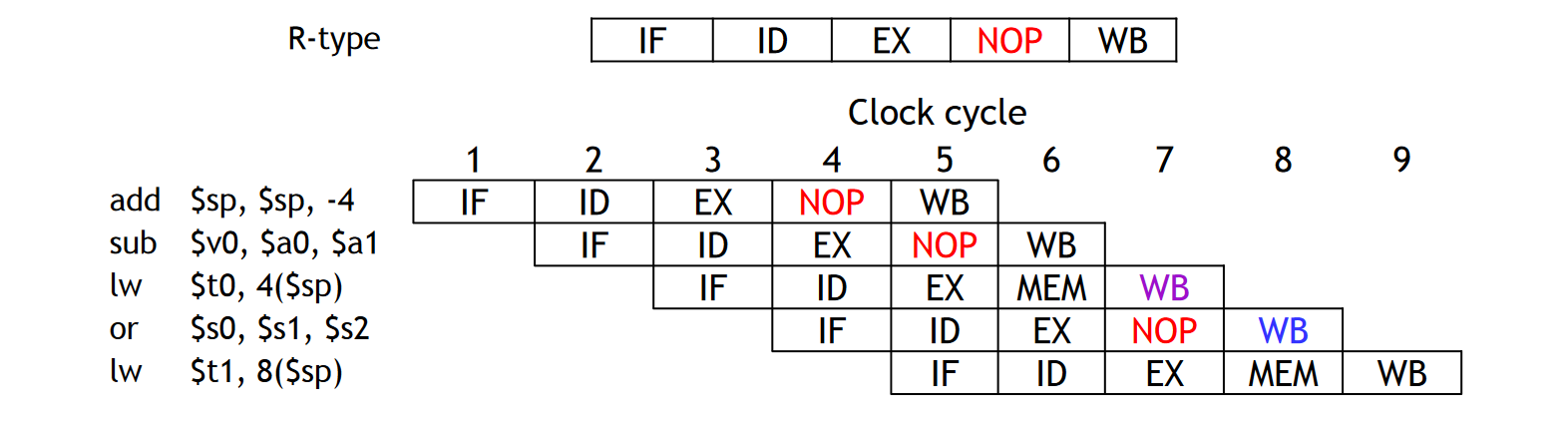
但是,并不是所有的指令都会经历上面的五大阶段,比如 R-Type 指令只需要 IF、ID、EX、WB 这四个阶段,不需要经历访存的过程。然而,每个工作单元(模块)每条指令只能用一次。同时,为了避免冲突,对所有指令来说,每个工作单元的使用必须在指令的相同阶段进行。
比如,如果出现了下面的情况:
- LW 指令在 WB 阶段(它的第五阶段)写入寄存器
- R-Type 指令在 WB 阶段(他的第四阶段)同时写入寄存器
那么寄存器写入端口就炸了。┑( ̄Д  ̄)┍
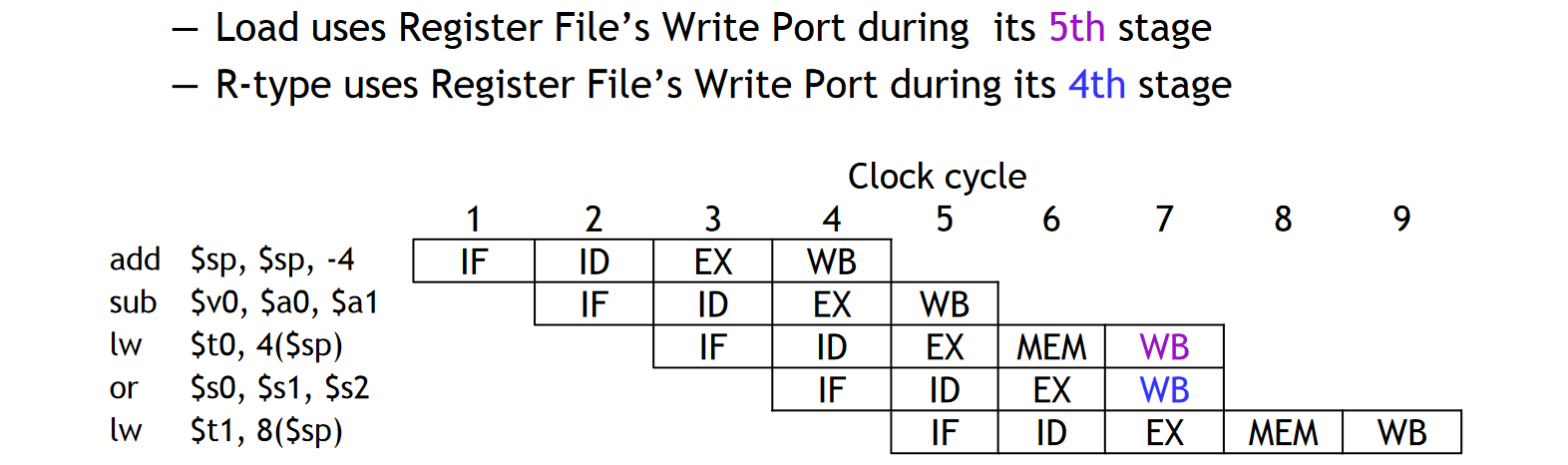
为了避免这种情况的出现,我们需要保证所有指令的执行过程都经历五个阶段,如果一条指令不需要某一阶段的时候,我们认为为其加上 NOP 阶段,代表本阶段此指令什么都不干。